Some not so silly ML questions #1
I am part of a group at work that’s attending a course on ML Accelerators. Few of the early sessions has us go through some of the famous ML model architectures. There were few questions that were asked to the professor that at first sight felt unnecessary but immediately made me write notes to research later. Here’s the first batch of these questions and my takes on it after thinking more on them.
Why do we talk about linearity and non linearity in Deep Learning models?
If the DL model is linear, it would just be a fancier linear regression problem statement.
y = W_3(W_2(W_1x + b_1) + b_2) + b_3
Awful like
y = Mx + c
In an intuitive sense without non linearity, you’d just be plotting lines like a linear regression model would, without actually being an improvement on it. Non Linearity forces the model to fit better.
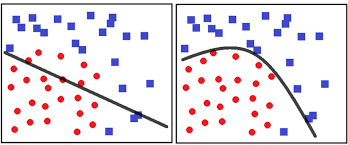 Line & Curve
Line & Curve
Think if a linear network could chat with you and move us past the convo of Turing Test into the AGI / ASI world.
The XOR problem is a great example of shortcoming of a Linear Model to solve a basic problem in the form of XOR, and it getting resolved with some non linearity + and another layer.
Activation Functions provide non linearity in a NN, without it everything would just seem to be matrix multiplications of weights and input, which resembles a linear regression problem.
y = ReLU(W_2(ReLU(W_1x + b_1)) + b_2)
How can a Neural Network so strong, so giving, run on ReLUs?
We went through why non linearity is important. Why ReLU?
The Rectified Linear Unit (ReLU) or ReLU sounds fancy, but its just
f(x) = max(0, x)
If the input is positive, it stays the same. If it’s negative, it becomes zero. It looks simple, but it just does the job.
ReLU provides this non-linearity by introducing a change in gradient at zero. This allows the network to perform Piecewise Linear Approximation. By summing these ‘bent’ functions, the model can approximate any continuous, non-linear function a capability known as the Universal Approximation Theorem.
It also forces a stop for calculations when the signal is negative - sparsity. Because it outputs an exact zero for any negative input, it effectively deactivates neurons that do not contribute to a specific feature.
There are other activation functions, sigmoid & tanh. ReLU’s faster, and for many usecases better.
Is pooling necessary for a CNN to converge?
If you ever saw a DL architecture with CNNs you’d see blocks of CONV-POOL layers. Always accompanied one after another
When AlexNet was conceptualized, we lived in the time when good compute was rare and not exactly that accessible. Looking back, back in 2012 the high-end GPU for personal computing came with ~3.0 to 3.9 TFLOPS while today we can get an 80-100+ TFLOPS NVIDIA GPU in your personal machine. That’s a big 25x improvement.
Pooling as a feature provides you dimensionality reduction, which meant it helps you train models more efficiently (indirectly reducing the parameters for next layers) and possible on smaller machines. But you also lose a lot of information.
Leveraging Pooling for efficiency alone is a wrong take. Pooling carries another two heavy advantages - invariance (invariant to small changes in the image), and also receptive field (you cover more of image).
But in 2026, when you have enough compute on your laptop & then some on Google Colab and a lot more on cloud, what happens when you train a CNN without pooling? Would it work?
From what I read, the answer is yes.
In 2014, the paper “Striving for Simplicity: The All Convolutional Net” demonstrated that pooling could be replaced by strided convolutions without losing accuracy.
Instead of using a 2x2 Max Pooling layer to halve the image size, you use a convolutional layer with a stride of 2. This allowed them to train a network to learn its own downsampling filter rather than using a fixed mathematical function like “take the maximum value.”
In Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs), you’ll see this applied - strided convolutions instead of pooling. Learnable vs hardcoded logic.
For CNNs, why do we take the Max in Pooling?
Pooling in CNNs is the block that looks at a large grid of numbers and replaces a section of them with a single value that best represents that neighborhood, often the maximum.
An intuitive sense of why max is used that came to me was you’d want your model, or kernel to learn the signal, learn where the tyre in a car is or eye in a photo is. Not learn “this is not a tyre”, “this is not an eye”. As you can see, the latter route is endless. Max pooling just does that. The network passes that high-activation signal forward. While that’s true but a better answer to the the need for pooling is actually more on the lines of translation invariance.
If the eye shifts by three pixels to the left because the person tilted their head, a Conv layer might see that as a totally different signal. Max Pooling looks at block and says, “I don’t care exactly where the eye is in this 2x2 square, just that it’s there.” This makes the model robust to small shifts and distortions.
Why do we use MSE as loss?
MSE is Mean Squared Error. You’ll see it pop up in a lot of places when we talk about loss. But do note, its just another loss function.
(MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2
)
A loss function’s whole purpose is to help identify the difference between what your model predicted and the truth. So, for any good model, you need a loss function that captures that.
For common use cases, MSE’s a simple & elegant loss function, and perhaps for a layman easier to explain than a complicated one like the ones in GANs. We don’t use MSE for classification problems.
But why not just leave it at difference? Why do you have to Square it?
We square the error primarily to penalize outliers and ensure a smooth gradient. And also you don’t want your error to cancel out each other.
MSE is also a Convex Function when applied to a linear model. Because it's smooth and has a clear bottom, Gradient Descent algorithm can easily work to find the minimum error without getting stuck as easily. But again, this MSE curve is actually a gross oversimiplication of the problem we have in a typical Neural Network - with activation functions in play, it is non convex with our work to find a local minima that works for us.
There are other loss functions that are far more used widely for DL. Cross Entropy loss (classification problem statements), KL Divergence (VAEs), Contrastive Loss (think CLIP).
Good references